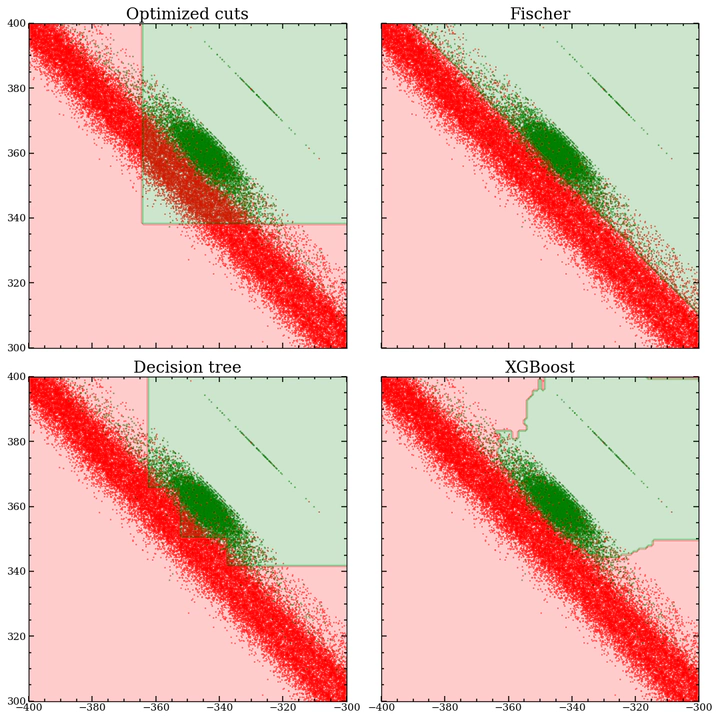
 XGBoost ecision boundary for two parameters in the ATLAS dataset
XGBoost ecision boundary for two parameters in the ATLAS dataset
This project was done in collaboration with Jonas Vinther, Johann Bock Severin and Jakob H. Schauser during our third semester as physics undergraduates. Check out their GitHubs!
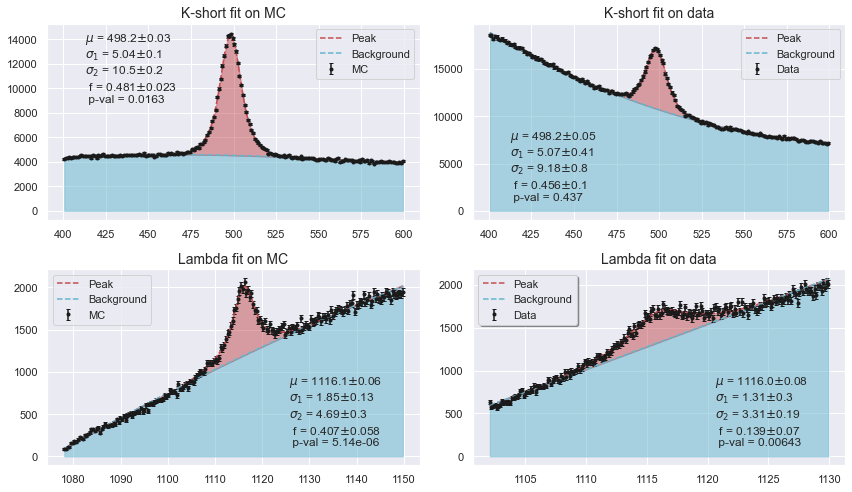
In all branches of physics, new discoveries are made by identifying some signal peak upon a background of noise. In High Energy Physics, this could be the peak of a new particle found amongst the almost uncountable amount of collisions happening every second the Large Hadron Collider is running. Only a few collisions actually produce interesting particles. This makes it crucial to be able to classify which detections are part of the actual signal, and which are not. In this project we employed a range of statistical methods and machine learning algorithms to get the best estimate of the masses of different $V^0$ - particles, in both simulated data and real data.
As can be seen in the top figure, among some of the methods tried were simply doing some linear cuts in the feature space, found by simple annealing, using Fisher’s discriminant analysis, a simple decision tree and some boosted decision tree algorithms, of which XGBoost ended up being the method of choice. We ended up getting an accuracy of 99.7% for classyfing signal and background.
Perhaps the most exciting thing from this project was the ability for our models to learn what a true label looked like in real data without having those labels. Overall, the LHC dataset is fantastic as a learning platform for both classification and regression problem. If you would like to get involved, reach out to Troels C. Petersen. Anybody who wants to read the resulting report is welcome to do, by clicking the link at the top of the article, where we also explore a range of more or less wacky ideas.
Christian Kragh Jespersen
PhD Candidate in Astrophysical Sciences
My research interests are at the intersection between Machine Learning, galaxy formation and evolution, big surveys, and cosmology